

Conventionally, natural language generation for dialogue agents may be viewed as a statistical learning problem: determine the patterns in text and generate similar responses. However, dialogue can also be a goal directed process where speakers attempt to accomplish a specific task. Reinforcement learning (RL) algorithms are specifically designed for solving such goal-directed problems. However, naively applying RL to NLP problems requires samples collected online through human interaction, an expensive process. In this paper, we explore how we can we use Offline RL to train dialogue agents solely using static datasets.
Traditionally, dialogue agents are trained using Supervised Learning (SL) over data collected by a human. We list two main reasons to use RL over SL in training dialogue agents.
- SL does not guarantee that the agent learns to complete the task, while RL explicitly optimizes for the goal.
- Through training, RL can produce better behavior than the dataset policy. This is useful especially if the dataset collected is suboptimal.
There are two main reasons we use Offline RL.
- Naively applying RL to train a dialogue agent requires dialogue to be generated online, either through self-play or through human-in-the-loop. Offline RL can use static data, removing the requirement of online training. Consequently, we can leverage the power of large datasets to train our agent.
- Training a language model using RL might result in the LM generating non-intelligible language to distribution shift. Previous work solves this by applying strong priors to the LM during finetuning. However, Offline RL implicitly handles distribution shift, removing the need for restrictive priors.
We choose the Craigslist Negotiation Dataset, which consists of bargaining dialogue over items scraped from Craigslist. The aim of the agent is to answer questions about the item and bargain with the buyer to sell the product. The seller is rewarded proportional to the final sale price. If the seller is unable to sell the product, they are penalized.
Our model consists of three phases:
- Template Generation: We employ GPT-2 to generate candidate responses to an utterance. We finetune GPT-2 on the task-specific dataset conditioned on the context and all utterances.
- Ranking: We create a matrix of templates and price candidates. We then use a Q-function to generate scores for each candidate response
- Selection: From the template matrix, we select the utterance and price tuple with the highest score.
The model architecture is summarized in the diagram below.
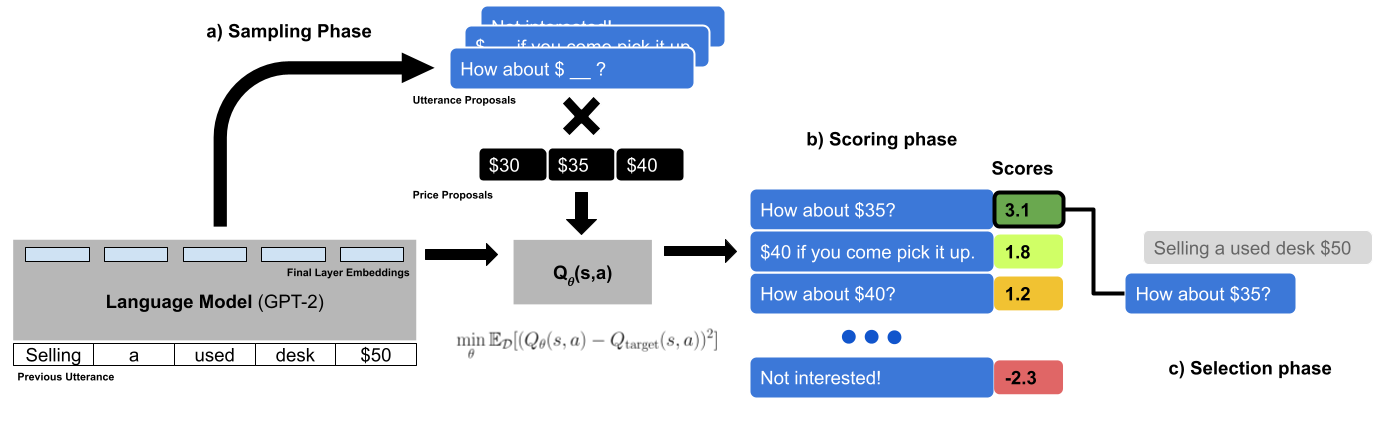
We train each component individually as follows:
- GPT-2: We mask prices on the masked dataset with a special $PRICE token and use it to finetune GPT-2.
- Q-function: We train the Q-function using Offline RL. We experiment with EMaQ, BRAC and CQL.
Here you are! These are a set of examples of our agent talking to human evaluators. Press the buttons on the bottom to scroll through the results.
{{examples[index].title}}
Description: {{examples[index].description}}
List Price: ${{examples[index].price}}

Thanks for your interest! You can cite this work through the following BibTeX entry: